

Unexpectedly, one of the best use cases for Large Language Models to date has been its role in web scraping. LLMs are the most dynamic, logical and flexible data extraction tool we've ever seen and the web is the largest source of data on earth. It's a match made in heaven.
In this post I'll go over tips and tricks for how to best approach web scraping tasks with AI.
Why is AI perfect for web scraping?
The core value AI provides in web scraping is converting unstructured to structured data. It's able to take a jumble of text and make sense of it for you. Reducing that jumble of text to only the values you care about is where the magic lies.
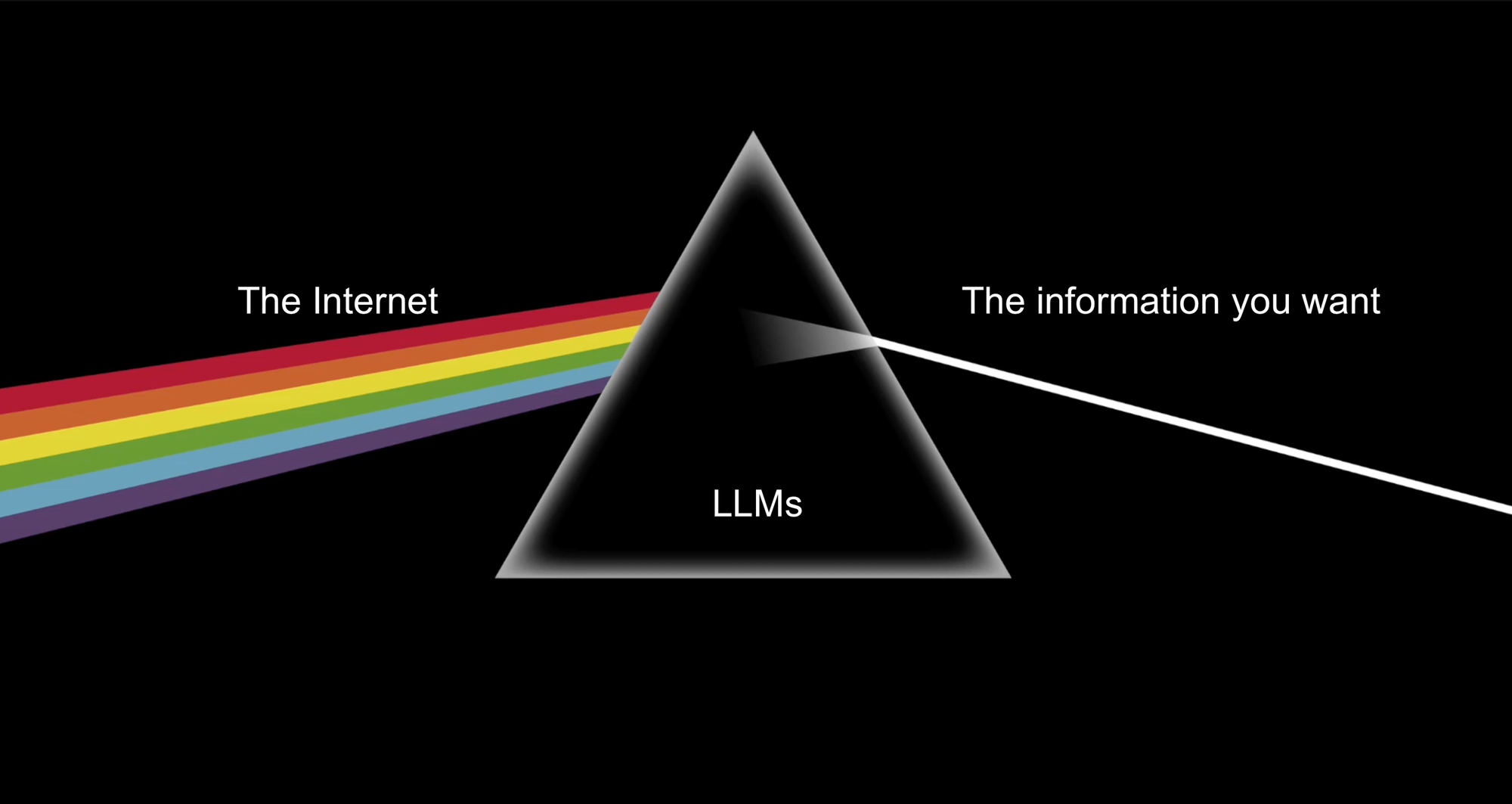
Basic web scraping can do this but it's much more brittle and must be tailored to specific websites. Any minor changes in structure or page rendering causes conventional scrapers to crumble while AI handles changes gracefully.
Converting a company directory to a list of company names, a restaurants website to a single address or a list of websites into their respective categories. It reduces the noise of the internet into the key value you care about and can do so at scale, for cheap.
Extracting Data Tips
We've learned a lot through trial and error while web scraping with AI. Here are some of our best tips.
Reduce the noise
The more you can reduce the context you're passing into your AI prompt, the better the AI will perform. Try to cut out anything that's not necessary for the scraping task. Things like footer, sidebar or even the format the data is presented in can be a distraction to the LLM that will impact performance.
There are often very clear tags you can filter out if you want to exclude components like the footer or header across your scrapes.
The raw HTML for a website is often the most informative format the content can be analyzed in since it contains the page structure and embedded links. The downside is that HTML is extremely verbose. If you can get away with only scraping the text that can cut the size of your prompt in half. Similarly, if you can convert the content into a lighter format like markdown that also helps a ton.
Use LLM functions
Functions were a groundbreaking upgrade to Large Language Models because they let you rigidly define schems that the output should abide by. For the purpose of web scraping this is wonderful as the jumble of text on a page can reliably be reduced to single values.
Functions are slowly being deprecated in favour of 'structured outputs'. Practically these approaches to structuring data are the same but the latter is simply more reliable as there is additional output checking being performed to ensure there's no hallucinations of keys or json structure.
Give fallbacks
This tip is universal across most LLM tasks but giving the models a fallback option is one of the best ways to avoid hallucinations.
If you're extracting company names from some directory and the LLM sees a page with no company names, it'll try its absolute best to fulfill your request even if that means making up a company name.
Providing a fallback gives the model an easy out and a clear way for you to detect failures. I often like to tell the model to return UNKNOWN if it's ever even remotely unsure about a value it's extracting.
Navigating websites with AI
Traverse with links not clicks
When most people think of AI web scraping, they're imagining an AI taking control of a browser and clicking around. This is a surprisingly daunting workflow for AI to accomplish. Several unavoidable issues arise (covered in the following 'Common Issues' section) that cause the AI to be extremely unreliable and expensive at scale.
Luckily, all web pages on a website are connected in some way via Links. This is the same way google's crawlers can explore your website for content. Using the links present on a page is a great, structured way to have the AI select it's next path without needing vision capabilities or the ability to manipulate a browser. It's called a 'sitemap' for a reason since it's literally mapping out your website!
Scrape all the present links on a page and present them to the AI for it to contextually select the next page to crawl.
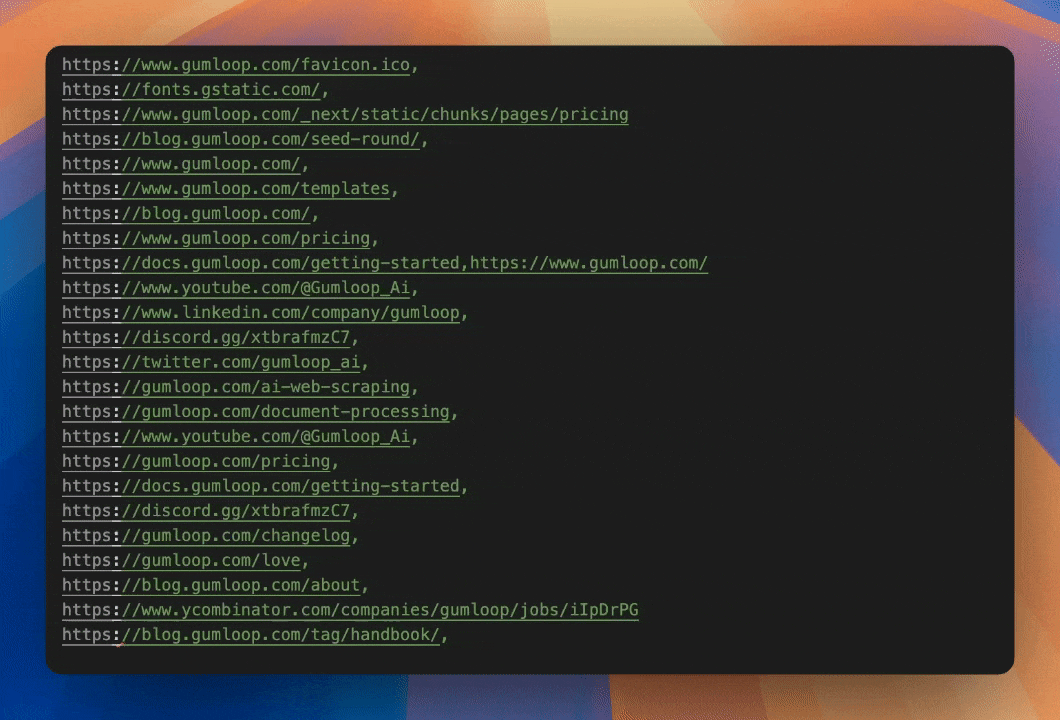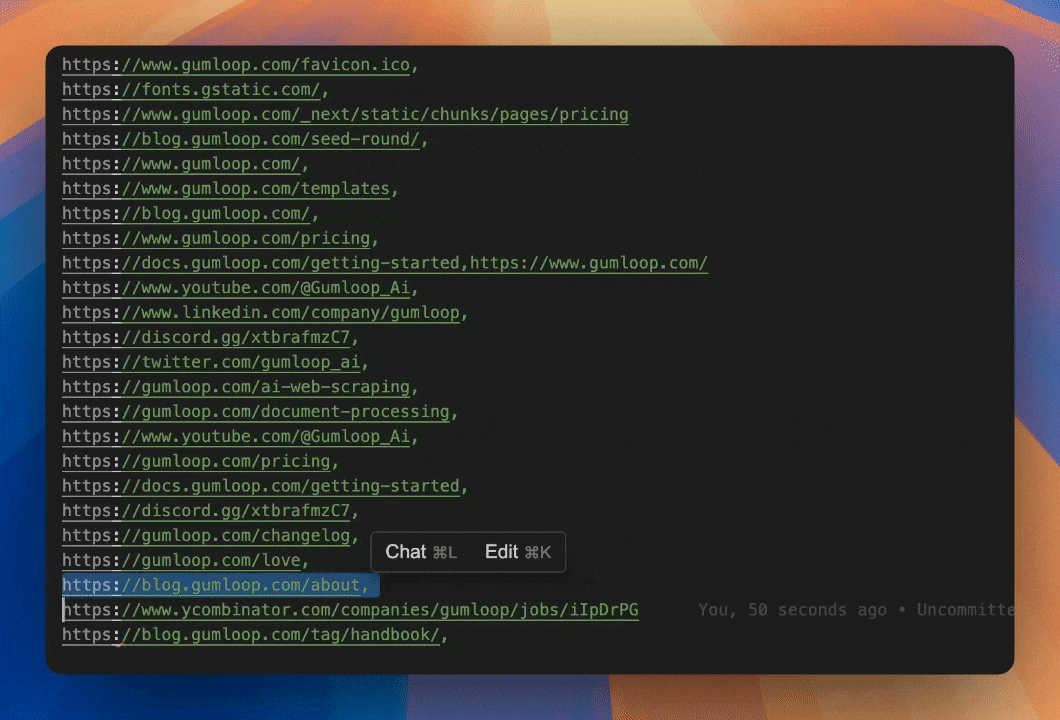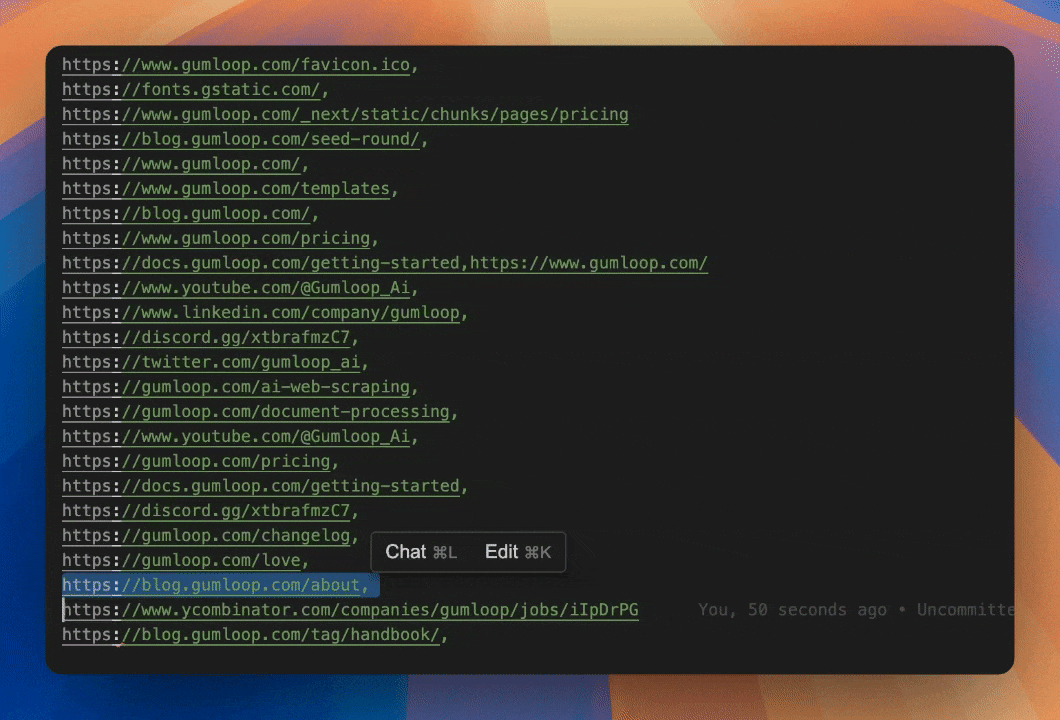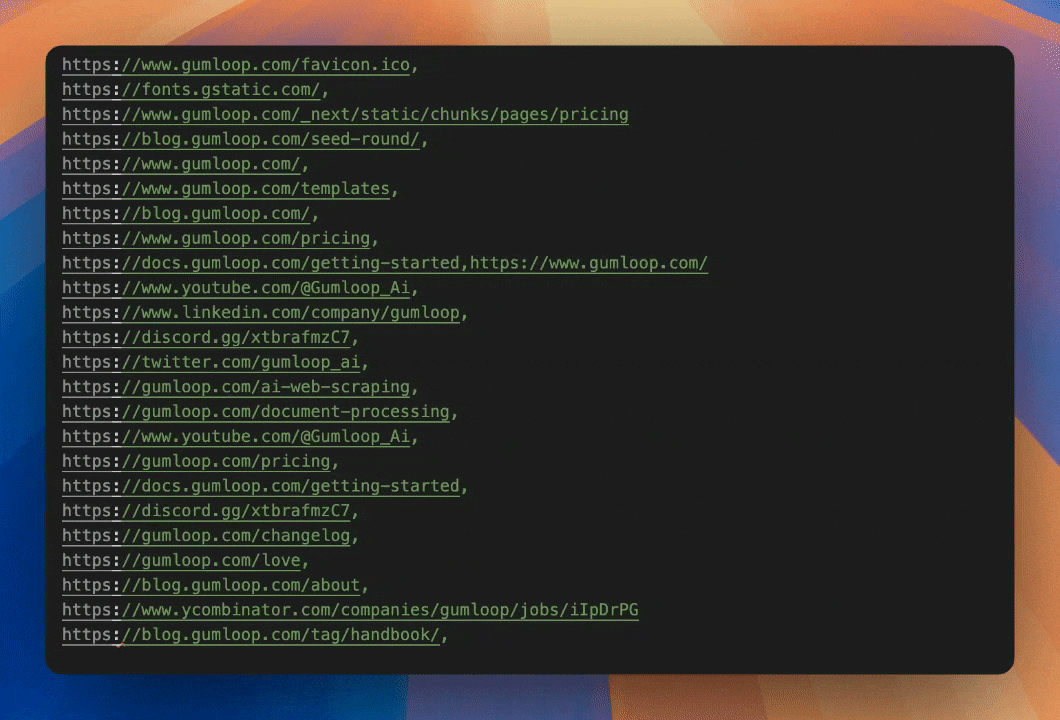
Select the next link with AI
AI can ingest all the possible urls and semantically determine the best page to scrape. No need for hardcoding the crawl or keyword matching. Simply describe what you're looking for and let the AI reason its way there.
If you wanted the page on a company website about their management, you can describe what you're looking for and the AI can make a judgement call that domain.com/our-corporate-family is the most likely candidate from the available links.
Filter links without AI first
This is a minor tip but 'reducing the noise' applies to this url selection step as well. A page might contain hundreds or thousands of links. Many of these can be filtered out before the AI gets involved at all. If you want to traverse a website from the landing page, you can automatically filter out any links that don't contain the root domain. If you only want blogs you can filter out any links without that keyword.
Basic scrape Vs. Agent Browser Navigation
Scraping and extracting/analyzing data is right up the LLM's alley but interacting with the website is a different story.
We recommend sticking to the basic scraping of the page, formatting the content if necessary and then querying your LLM. This will normally achieve 90% of the value for 10% of the effort compared to letting the AI autonomously navigate. Many seemingly benign aspects of websites can completely destroy 'agentic web browsers' from accomplishing their tasks.
Popups
Unexpected popups for promotions, cookie related questions or for login cause massive problems for AI web scraping tasks.
The AI might be tasked with categorizing a startups industry but if all it can extract is a login modal's text the task is unlikely to be successful.
If you're doing any sort of vision based, AI web browsing a popup can be the difference between a clear legible button and a completely unsolvable problem for the AI.
Scrolling
Often times when scraping directories, the data might only populate when you reach the bottom of the page. This load on scroll will cause some issues if you're not expecting it.
Scrolling to the bottom of the page (with some cutoff) by default is a great way to ensure your content is loaded before the content is scraped.
Clicking
Clicking on a button is trivial for a human but can cause a world of pain for an AI. Especially if there is anything out of the ordinary causing the button to be obstructed or rendered unexpectedly.
Clicking for pagination, to view hidden content and for navigation can cause serious mayhem. Avoid it and traverse the website via links wherever possible.
Autonomous web agents in practice
We built an autonomous web agent into our platform earlier this year as an experiment and were underwhelmed by the results. All of these issues listed above made the agent stumble ~10% of the time. Even if it was rare, it was enough to never trust the agent which disqualified it from any important use case.
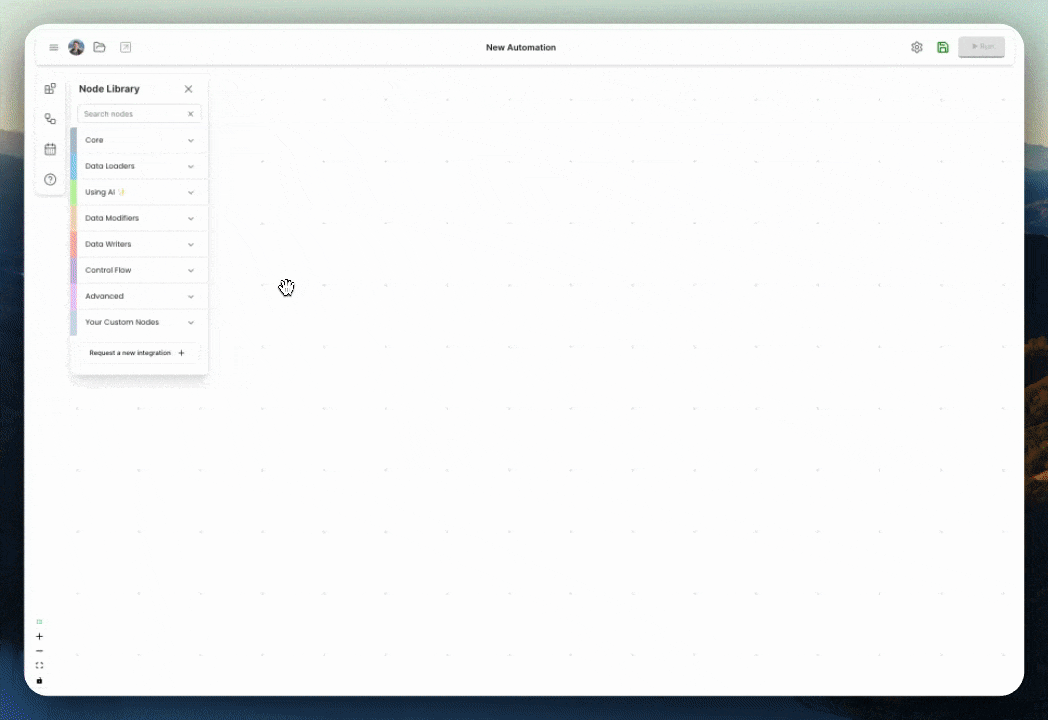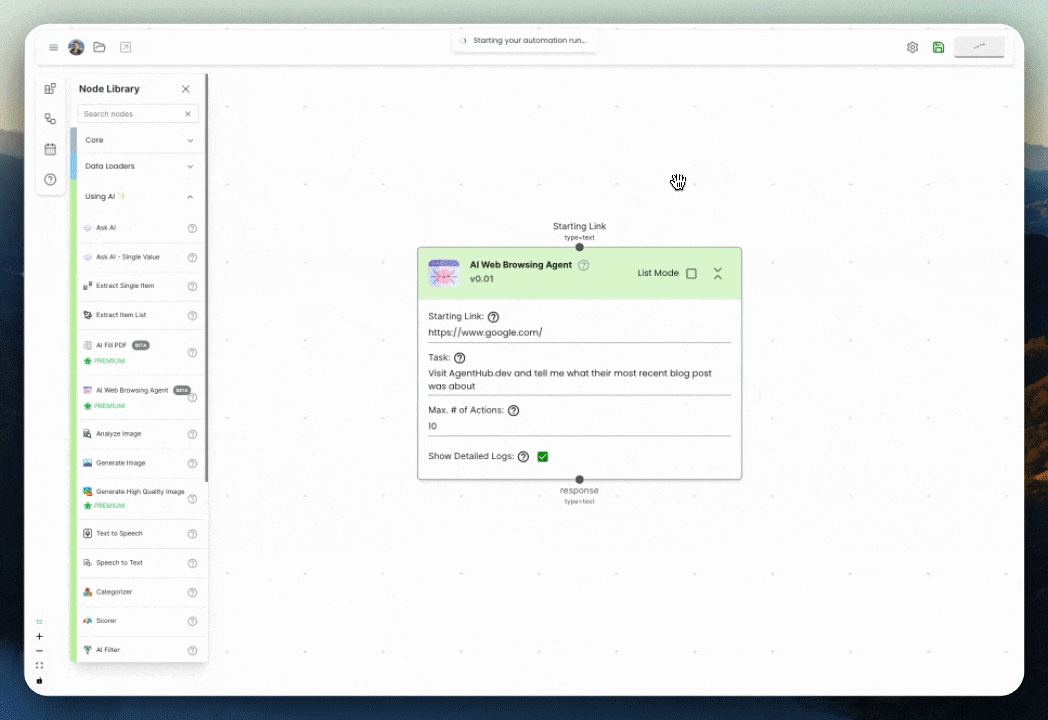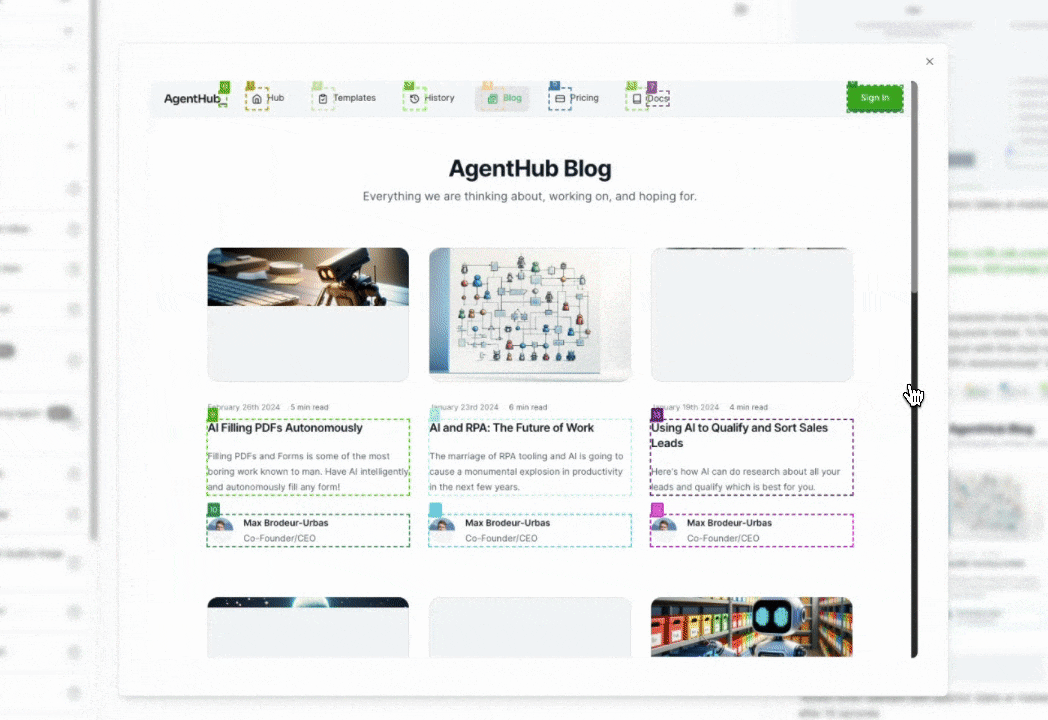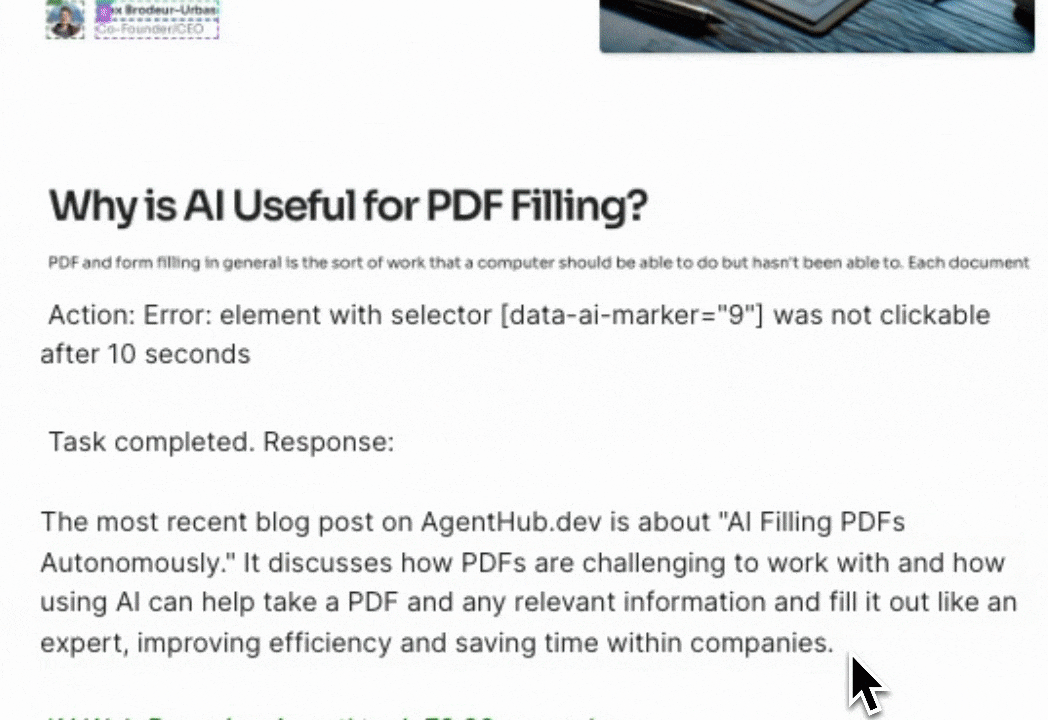
Gumloop and AI Web Scraping
On Gumloop, we handle most of this web scraping complexity for you or make it easy to build your own web scraping systems. The nodes on our platform provide the fundamental building blocks for web scraping work and allow you to design a flow totally custom to your use case.
To run AI web scraping flows completely for free, check out Gumloop's web scraping functionality here.